
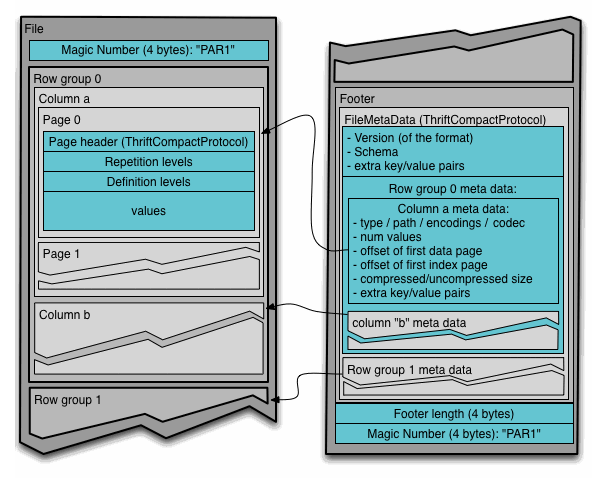
Apache Parquet es un formato de almacenamiento en columnas disponible en todos los proyectos que pertenecen al ecosistema Hadoop, independientemente del modelo de procesamiento, marco o lenguaje utilizado.
A diferencia de los modelos de almacenamiento tradicionales que utilizan un enfoque orientado a filas, Parquet almacena datos en forma de columnas planas, donde los valores de las columnas se almacenan uno al lado del otro. Este modelo tiene algunos beneficios:
- La compresión de columnas es más eficiente
- El algoritmo de compresión se puede especificar por columna
- Las consultas “anchas” (que usan varias columnas) son más eficientes
Parquet se creó para admitir la compresión y la codificación de manera eficiente, es posible especificar la compresión por columna y está optimizado para trabajar con estructuras de datos complejas de forma masiva.
Todos estos beneficios se deben al algoritmo de ensamblaje y trituración de registros descrito en el documento Dremel de Google e implementado como parte del núcleo de Parquet.
Data Warehousing y Business Intelligence
